Hello,
We received the following the request from ALICE via GGUS
- Recall of files not present on the disk buffer or RAL::CTA: if a file is not on the disk buffer, an xrdcp command to ALICE::RAL::CTA should automatically trigger the recall, without a need to use ‘xrdfs prepare’. This functionality is present on all custodial storage elements with tape backed, including CERN::CTA
We were under the imporession that the only way to trigger a recall from EOS/CTA is via xrdfs prepare -s …but apparently ALICE performs recalls simply with an xrdcp command and on CTA instance at CERN!
Can you please shed some light here?
Many thanks,
George
Hello,
looks like we are lacking some documentation for this one. Sorry for that, we’ll add this very specific Alice tweak in our documentation.
To enable these implicit prepare for Alice workflow you need to add the following WFE workflow on top of the standard ones for Alice directories:
sync::offline.default.
Best regards,
Julien Leduc
Many thanks for this Julien and no problem at all!
George
Hi Julien,
Sorry to come back to this. ALICE reported that ~25% of their attempted recalls failed with the following error message
xrdcp (TPC==0) exited with exit code 54: [ERROR] Server responded with an error: [3005] Unable to open - no disk replica exists
which is a message I see for all ALICE recalls in xrdlog.mgm (and on all my tests which do succeed nevertheless in staging the file on disk). For some files there are a few "SYNC::OFFLINE events and for other more.
They mentioned that “Recalling the failed transfers after a day usually results in 100% success”. I only noticed that some of these files had 132 "SYNC::OFFLINE events associated with each one of them.
Is this how sync::offline.default. workflow supposed to work? Does it have a certain failure rate no matter waht or are we missing sth else?
George
What I guess is happening on your side is that the Alice files stay in the retrieve space and are automatically garbage collected when they have been there for 24hours (or what you configured in your GCDs).
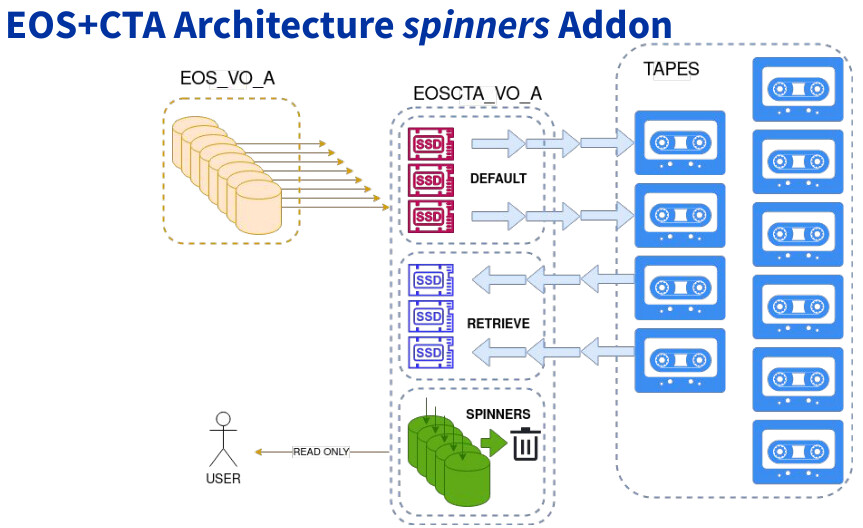
The Alice workflow at CERN is slightly different than for the other VOs:
- the files are staged from tape with this offline WFE
- they land in the retrieve buffer
- they are sent to spinners space where they stay until GC’ed when the disks are full in this space
This workflow is very different than for other VOs… This is what I referred to as the spinners Addon model in my presentations at the various EOS workshops (see my last EOS WS presentation )
This addon is enabled at the eoscta instance level and requires one more space with hard drives to provide capacity.
At this point I am not sure how this fist in RAL infrastructure because it would make more sense to have these files in echo.
I guess this is something we may need to discuss in a dedicated meeting: I have some ideas to make the Alice workflow fit in a multi-vo environment with spinners space managed in eoscta instance.
Best regards,
Julien Leduc
Thanks for the detailed reply. We are aware of the spinners Addon you have in the ALICE EOSCTA instance at CERN. There are discussions in progress whetner we will set this up at RAL. I will definitely let you know if we do and many thanks for suggesting a meeting to discuss.
But irrespective of the spinners and GC in the retrieve space (by the way, we have absolute_max_age_secs=86400), there is something I dont understand: ALICE confirm that they are doing an xrdcp for all the files they want to recall.
We do a xrdcp of the file to a remote storage, in this case ALICE::CERN::EOSALICEO2
How is it posiible that this xrdcp works for most of the files but not all? And what is strange is that the client message that ALICE reports for these 25% failures (Unable to open - no disk replica exists) is seen in the MGM log for all the recalled files.
I am confused…
George
I can just guess from this that some xrdcp out of the retrieve space are very likely to be triggered before the staging has been issued, before the file lands on disk and then some after the file has been GC’ed.
All these are going to indicate no disk replica in eos logs because indeed: there is no disk replica available for immediate transfer when this is triggered.
You need to understand this from your logs looking at a few specific files.
At T0 we have only 2 use cases that I presented in the attached presentation:
- eoscta instance with no spinners space → FTS manages all transfers (notably the eviction out of the retrieve space)
- transfers that are not FTS managed → eoscta instance with spinners addon
Other combinations outside these 2 must be discussed in a dedicated meeting and carefully evaluated as they are likely to raise many more problems.
Best regards,
Julien